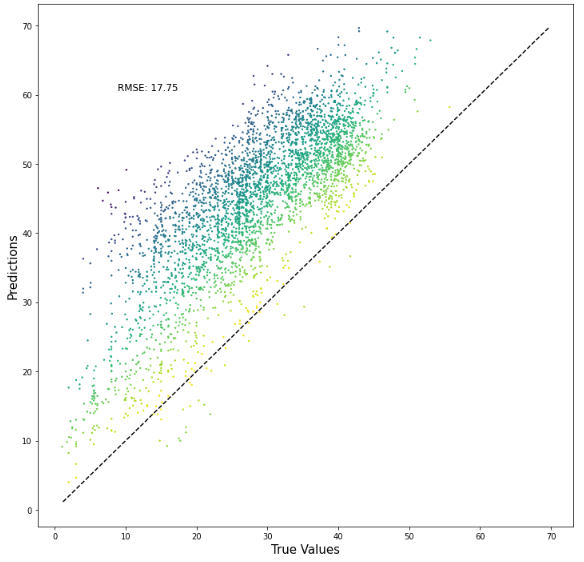
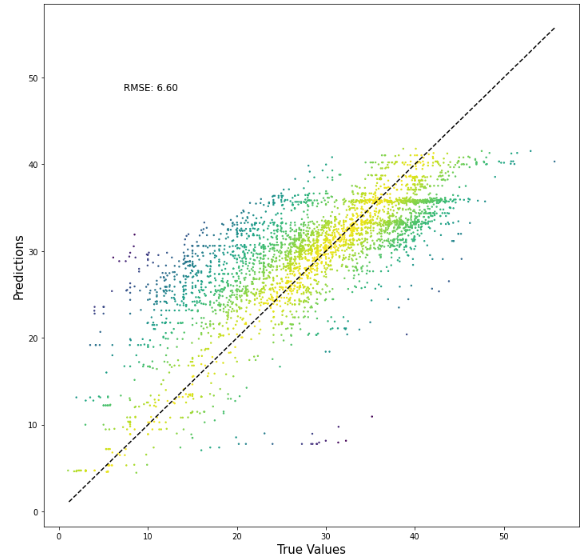
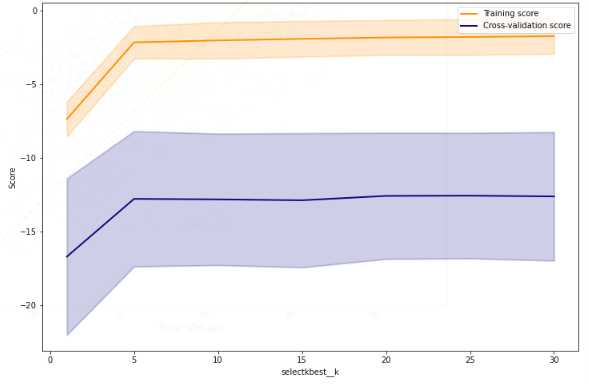
Using Advanced Data Featuring (Python) to build a model that predicts the day-ahead price of power in Spain.
Project 5: Predicting Energy Price. ML
In this ML project we will create a model that predicts the day-ahead price of power in Spain with Python.
As in previous projects, we will cover some of the most interesting steps and findings but not all of them. Personally, I would recommend that you download the code (Jupyter notebook) and the datasets (CSV files) for a better understanding.
Our dataset (power_market.csv) is composed of:
date: date of the observation ”%Y-%m-%d”
hour: hour of the observation, [0 - 23]
fc demand: forecast of demand in MWh
fc nuclear: forecast of nuclear power production in MWh
import FR: forecast of the importing capacity from France to Spain in MWh
export FR: forecast of the exporting capacity from Spain to France in MWh
fc wind: forecast of wind power production in MWh
fc solar pv: forecast of PV solar (solar panels) power production in MWh
fc solar th: forecast of thermal solar power production in MWh
price: power price for each hour in €/MWh. This is the target we want you to predict.
And the scoring.csv:
We start off by importing the libraries we need. As well as the common machine learning libraries (sklearn, pandas, numpy, etc) we use astral to calculate sunrise and sunset times, and xgboost to use their gradient boosting regressor.
Exploratory Data Analysis
We create the function “ESHolidayCalendar” to check whether or not certain days are a holiday in Spain.
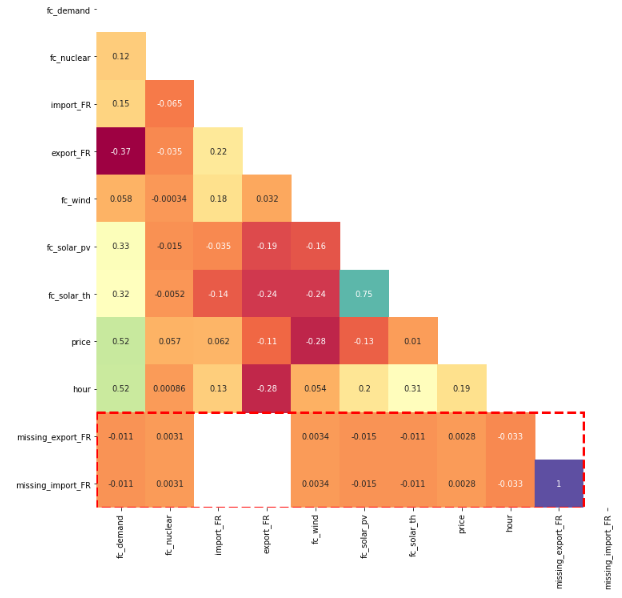
We detected that there are 26 null values in our dataframe (df.isnull().sum()). We plot a correlation matrix to make sure that our missing values are not correlated.
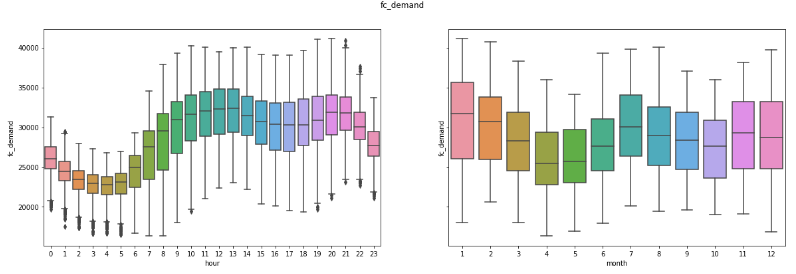
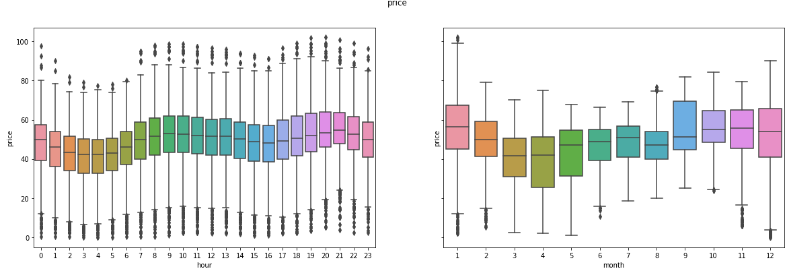
We can also detect some patterns with visualizations.
Demand by hour and month
Price by hour and month
Feature Engineering
This DateEncoder is a result of our iterative feature engineering process. As we discovered new patterns in the data we added more features. It works in the same way as FunctionTransformers, so it can be included as a step in a pipeline, and its parameters can be changed so it behaves differently (include some features or not). This allows for clean pipelines, and prevents us from having to make copies of dataframes for every type of preprocessing we want to do.
These are the features it can extract:
season, which can be returned as a column of strings or as a series of encoded columns
is_holiday, whether or not it is a holiday in Spain
is_weekend
is_business_day, the combination of the two previous features
sunlight, hours of sunlight
sun, whether or not the sun is up at any given hour (rounds to the nearest hour)
t_from_zenith, the hours away from the sun’s zenith
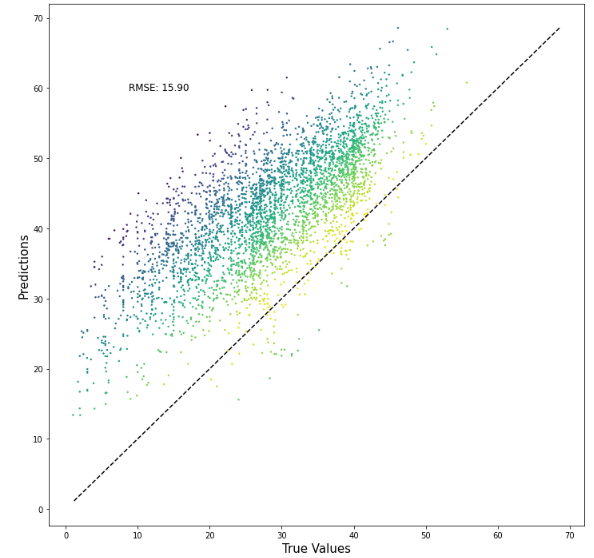
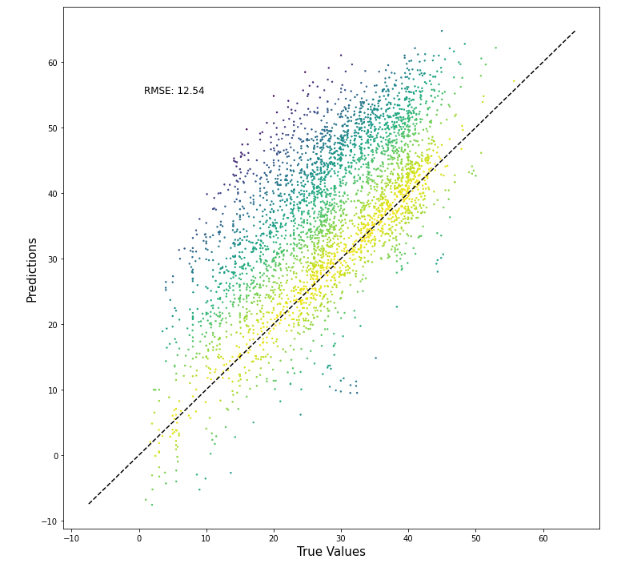
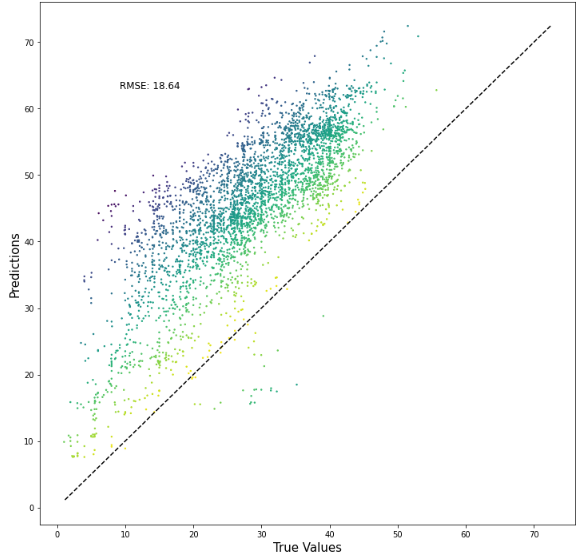
Feature Engineered XGBoost with Early Stopping- RMSE=6.60
Selecting the best number of features
Lastly, we checked whether we could improve the accuracy of our model by predicting with less paramaters as a measure to prevent overfitting. However, the result was that the more features, the more accurate our model.